Machine Learning 的步驟
本文圖片皆來自參考資料中的網站
Machine Learning (下文簡稱 ML) 具體應該有甚麼流程並沒有一個標準,根據網路搜尋的文章,大致上會把 ML 劃分為 5 至 7 個步驟,在一個沒有公定標準的情況下,我選擇以 Google Cloud Platform 發布的 The 7 Steps of Machine Learning 作為參考依據。 原文作者將 ML 劃分為 7 個步驟:
-
Gathering Data
取得訓練用的資料集,這是 ML 最重要的步驟,因為資料的品質和量會直接決定模型的好壞。通常資料會以 csv, json, txt, … 等檔案格式儲存。像下圖是以 DataFrame 形式載入的 csv 。

-
Data preparation
因為原始資料集可能存在缺失值、離群值,或是原始資料可能需要轉換才可以丟入模型訓練,所以在這個步驟要對資料集進行前處理,把可能阻礙訓練的因素排除。在這個步驟也常常利用資料視覺化來分析資料集裡各個屬性的特徵,像下圖是將年齡分布視覺化。

-
Choosing a model
考量訓練速度、占用資源、預測準確度等,在不同場景選擇最適合的演算法進行訓練。下圖是常見的 ML 演算法。

-
Training
這部分就是等待模型訓練完畢,可以藉由多執行緒、GPU、分散式運算等加快速度。
-
Evaluation
從資料集中抽出部分用以測試,其餘用來訓練,訓練跟測試的比例通常是 80/20 或是 70/30。
-
Parameter Tuning
測試結束後,調整超參數和訓練時的權重,嘗試讓模型去 fit 資料集,提高準確度。

-
Prediction
最後當模型的準確度達到一定的標準,就能拿來應用在現實的問題中。

DevOps
使用 DevOps (來源: aws) 的模式,可以在品質保證的前提下讓安全團隊、開發團隊、營運團隊在整個應用程式生命週期更緊密地結合,將以往手動且緩慢的程序自動化;使用快速且可靠地工具,協助工程師獨立完成通常需要動用到團隊的工作 (例如部署程式碼或佈建基礎設施),而這樣可以進一步提高團隊的工作速度。

總的來說, DevOps (來源: aws) 有這些特點:
- 速度: 微型服務和持續交付
- 快速交付: 使用自動化流程,加快新版本部署的時間,以利快速地創新和改進產品
- 可靠性: 確保應用程式更新和基礎設施變更的品質、利用監控與紀錄了解效能
- 擴展: 利用基礎設施即程式碼將基礎設施版本化,並提供易於使用的 API 來管理基礎設施,甚至能做到執行時調整環境
- 經過改進的協作: 讓開發團隊與營運團隊緊密協作,在開發時就將執行環境納入考量。強調擁有權和責任的價值
- 安全性: 使用政策即程式碼,以自動化的方式將不合規的資源自動加上旗標做進一步的調查,甚至自動使其符合規範
MLOps
MLOps (來源: google) 是 ML 和 DevOps 的結合。
資料科學家利用高品質的資料集和精確的演算法訓練一個出色的模型,但是真正的挑戰不是建構模型,而是建構集成式的的機器學習系統,並且在生產環境中穩定運行。運行一個龐大的機器學習系統可能會遇到許多問題,於是衍生出 MLOps 的概念。下圖便是 MLOps 想要解決的問題:

MLOps level 0: Manual process

此級別的 MLOps 成熟度最低,從訓練、測試到部屬完全是手動完成,並且無 CI (持續整合) 、 CD (持續佈署) 、 CT (持續測試) 機制,也缺乏監測工具。只能夠拿來應用在不頻繁更改模型的場景,每年僅部屬到生產環境幾次。
另外一個缺點是: 訓練模型和部屬模型的流程會將數據科學家與工程師分開,在移交的過程會出現訓練應用偏差,也就是模型在移交給工程團隊部屬到生產環境時出現差異,表現出不符合預期的行為、回應過慢、或是消耗過多效能。
MLOps level 1: ML pipeline automation

MLOps level 1 利用 ML pipeline 將收集資料、訓練、驗證、部屬串連起來並自動化,這樣能夠快速地更新、切換生產環境所需要的模型。在這樣的架構下,推送到生產環境的不是單純的模型,而是一整個 pipeline ,然而 pipeline 仍需 IT 團隊手動部屬。 ML pipeline 通常有以下特點:
- 生產環境的 CT: 系統會在生產環境中抓取新數據自動訓練模型
- 開發和生產環境的對稱性: 開發環境中的 ML pipeline 必須能在生產環境中使用
- ML pipeline 程式碼模塊化: 讓 pipeline 的部件可以組合、重複使用,甚至做到跨機器共享。此外,部件還能導入容器化,會更有利於:
- 將生產環境與開發環境隔離
- 生產環境可重現開發環境的程式
- 隔離 pipeline 的每個組件,讓每個組件擁有自己的環境、語言函式庫、版本控管
- 模型建構的 CI/CD
- 其他 (不一定需要): Data and model validation, Feature store, Metadata management, ML pipeline triggers
MLOps level 1 通常應用在 ML pipeline 不會頻繁部屬的場景,並且只需要管理幾條 pipeline 。若是需要頻繁嘗試新的機器學習演算法,以及頻繁更換 ML pipeline 的部件,則需要對建構 ML pipeline 的流程導入 CI/CD。
MLOps level 2: CI/CD pipeline automation

CI/CD automated ML pipeline 可將前述的 ML pipeline 套用 CI/CD 自動化完成,讓資料科學家快速開發新的 ML 演算法、自動建構、測試 ML pipline 部件、以及將其部屬到生產環境。簡而言之,就是將 MLOps level 1 的自動化程度提升,並且具有以下特點:
- ML 模型、 ML pipline 的版本控管
- 測試、建構、部屬服務
- 註冊模型、設置模型存放區
- feature store (可存放大量資料集並實現低 I/O 延遲的區塊)
- ML metadata store (pipeline components, client libraries, input/output artifacts,… 雜七雜八的資料)
- ML pipeline orchestrator (幫助編排 ML pipeline 流程的工具)
下圖是 CI/CD automated ML pipeline 大致的流程:

在此流程下,資料科學家只需要手動分析數據、分析模型,其他動作交由 CI/CD automated ML pipeline 自動化執行。
MLOps 的 OS 設計
針對 ML 的 7 個步驟思考 OS 能帶來甚麼優化
-
Gathering Data
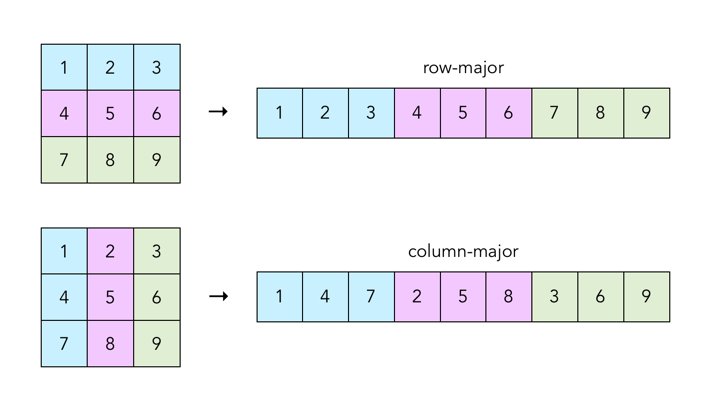
在這個步驟, OS 可以對常見的 csv, json 格式做優化,因為 csv, json 有固定的分隔符,易於解析讀取,也許 OS 可以在組語的層面支援這類型檔案,加速讀寫的速度。 此外 ML 的資料集通常有 row/column 的性質,也許可以在 os 層面可以優化資料在記憶體的排列方式,優化 locality ,並提供 system call ,讓使用者處理資料時聲明要用 row major 或 column major 來處理資料:
-
Data preparation, Choosing a model
這兩個部分 OS 可能很難提供協助
-
Training, Evaluation
調整 OS 的 Scheduling 演算法,讓 OS 可以有一個模式優先執行 training 的程序,大幅降低跟 training 無關的 interrupt ,待 trainning 結束時回復為一般的排程方法
-
Parameter Tuning
這個部分 OS 可能也很難提供協助
針對 MLOps 思考 OS 能帶來甚麼優化
-
ML Metadata table
首先考慮到 MLOps 有許多模塊,若單純將所有模塊都視為一樣類型的檔案或函式庫,每次提取時都需要對整個 inode table 效能會很差。所以我認為可以為強制為每個 ML 專案設置 ML Metadata,並且把所有 ML Metadata 放在一個獨立的 ML Metadata table ,每當使用者要開始編輯、訓練或測試一個 ML 專案時, OS 便會將 ML Metadata 和專案內所有用到的資源的位址載入記憶體。如下圖示:
 圖中 Metadata 裡會存放跟 ML 專案有關的資源的 inode 位址,比如專案的根目錄、函式庫、資料集、 pipline 用到的部件等,如此應該能大幅提升專案載入的速度,每當 ML 專案有變更時,會自動將新使用的資源 inode 加入 Metadata。
圖中 Metadata 裡會存放跟 ML 專案有關的資源的 inode 位址,比如專案的根目錄、函式庫、資料集、 pipline 用到的部件等,如此應該能大幅提升專案載入的速度,每當 ML 專案有變更時,會自動將新使用的資源 inode 加入 Metadata。此外,可以將各版本的模型位址存在 Metadata 中,這樣只需查找 ML Metadata 便能快速拿到所需的模型,不用將模型集中在 “模型存放區” 管理。
-
分配開發環境和生產環境的資源
一個機器學習系統可能同時要讓團隊進行開發,又要提供產品服務,又要更新資料集和模型,非常繁忙,因此資源分配很重要。也許 OS 可以提供偵測這些工作的高峰和離峰期,白天時將大部份資源分配給開發模型, product environment 和開發,晚上則用於更新資料集、 CI/CD。
-
偵測資料改變
對於 csv, json 這種格式的資料集, OS 可在離峰時段自動分析其分部機率、標準差、離群值等,定期產生報告以提醒使用者資料集近期的變化。
-
存取權限
明確劃分所有程序存取的權限,預設只讓生產環境中的程序擁有讀取該專案模型的權限,嚴格限制生產環境中的 client 修改模型和資料集,如果真的有必要讓 client 修改檔案,則提供資料備份、系統還原服務。 利用 OpenSSL 對每個 ML pipeline 和其對應的 client 加密、驗證,增強安全性。
參考資料
The 7 Steps of Machine Learning
DevOps
MLOps
微型服務
持續交付
基礎設施即程式碼
政策即程式碼
訓練應用偏差
feature store
ML metadata store
ML pipeline orchestrator